
1. Phương pháp lập bảng hỏi
Phương pháp điều tra bằng bảng hỏi là phương pháp phỏng vấn viết nhằm thu thập thông tin, dữ liệu sơ cấp, phục vụ cho mục đích nghiên cứu. Hoạt động thu thập dữ liệu được thực hiện cùng một lúc với nhiều người theo một bảng câu hỏi in sẵn, người được hỏi trả lời ý kiến của mình bằng cách đánh dấu vào các ô tương ứng theo một quy ước đã được thống nhất hoặc sẽ có một đội ngũ điều tra viên tham gia lấy ý kiến và đánh dấu câu trả lời vào phiếu hỏi. Sau đây là các bước cơ bản trong thực hiện xây dựng bảng hỏi điều tra xã hội học.
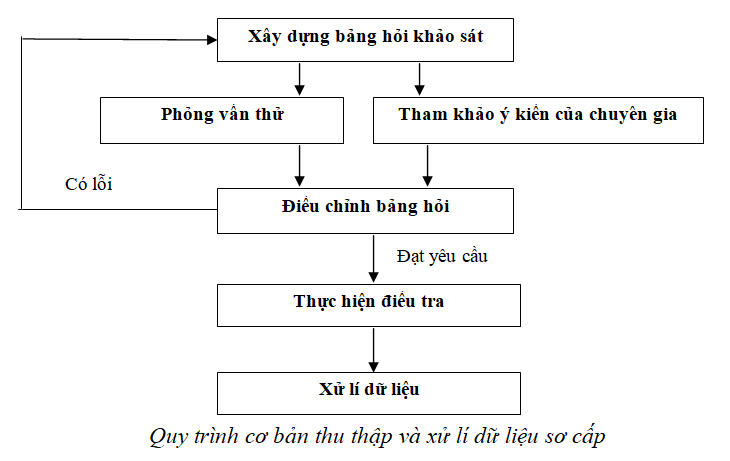
Cụ thể, chúng ta có 7 bước xây dựng bảng hỏi như sau:
Bước 1: Xác định mục tiêu và câu hỏi nghiên cứu
Đây là điều cần thiết mà người nghiên cứu cần biết để đảm bảo tất cả các câu hỏi được đưa ra trong bảng hỏi phù hợp với mục tiêu nghiên cứu và giúp trả lời được câu hỏi nghiên cứu đặt ra, cần đảm bảo rằng tất cả các câu hỏi trong bảng hỏi sẽ giúp thu được những dữ liệu phù hợp: tránh trường hợp thiếu dữ liệu cần thiết hoặc thừa dữ liệu không cần thiết.
Bước 2: Xác định đối tượng khảo sát và mẫu khảo sát dự kiến
Mỗi một nghiên cứu sẽ hướng tới nhóm đối tượng riêng, do đó bảng hỏi được thiết kế sao cho phù hợp với mục đích và đối tượng nghiên cứu. Ví dụ: Đối tượng khảo sát là một nhóm người dân trong một khu vực, hay một nhóm khách hàng đang sử dụng một loại dịch vụ... Chính vì vậy, chúng ta cần xác định rõ và đúng đối tượng khảo sát, mục tiêu khảo sát để thu thập được các dữ liệu cần thiết.
Bước 3: Xác định các cách thức thu thập dữ liệu
Có 2 kênh chính để thu thập dữ liệu sơ cấp bằng bảng hỏi: trực tiếp và gián tiếp;
- Trực tiếp: Chúng ta sẽ đến gặp đối tượng khảo sát và thuyết phục họ tham gia trả lời bảng hỏi. Cách làm này mất thời gian và công sức hơn, tuy nhiên có thể thấy hiệu quả ngay tức thì với số lượng bảng hỏi được trả lời khá nhiều và nguồn dữ liệu thu được thường có độ tin cậy cao hơn.
- Gián tiếp: Có thể gửi bảng hỏi online tới các đối tượng khảo sát qua email hoặc các diễn đàn và yêu cầu/nhờ họ trả lời. Với cách này, chúng ta sẽ không phải mất công sức đi khảo sát trực tiếp, tuy nhiên tỉ lệ trả lời thường thấp và dữ liệu thu được có thể thiếu tin cậy do các yếu tố chủ quan hoặc khách quan (người trả lời hiểu sai hoặc không hiểu câu hỏi...)
Bước 4: Xác định các câu hỏi trong bảng hỏi
Ở bước này, người nghiên cứu cần xác định các câu hỏi cần thiết và phù hợp trong bảng hỏi. Đâu là những câu hỏi cần thiết? Đó là những câu hỏi có thể thu được những dữ liệu cần thiết để trả lời được các vấn đề mà nghiên cứu đặt ra và hoàn thành mục tiêu nghiên cứu.
Bước 5: Sắp xếp thứ tự các câu hỏi trong bảng hỏi
Sau khi đã xác định các câu hỏi, người nghiên cứu cần sắp xếp các câu hỏi theo thứ tự phù hợp. Việc sắp xếp thứ tự của các câu hỏi cần có sự logic để cấu trúc của bảng hỏi hợp lí, tránh gây khó khăn và phức tạp cho người khảo sát. Ví dụ: Những câu hỏi chung và tổng quát cần đặt trước những câu hỏi đi sâu vào chi tiết, những câu hỏi quan trọng không đặt ở cuối cùng vì khi đó, người trả lời phiếu khảo sát có thể đã quá mệt và bỏ qua hoặc không tập trung trả lời.
Bước 6: Phỏng vấn thử và tham khảo ý kiến chuyên gia
Để hoàn thiện được bảng hỏi, đây là bước vô cùng quan trọng. Một bảng hỏi được thiết kế ban đầu thường có thể gặp các lỗi như câu hỏi đa nghĩa, câu hỏi không rõ nghĩa, câu hỏi khó hiểu hoặc dễ bị hiểu sai… Do đó, ngưởi làm nghiên cứu cần khảo sát thử với một số người tham gia nằm trong nhóm đối tượng mục tiêu thông qua các cách thu thập đã xác định ở bước 3 nhằm phát hiện ra những lỗi này. Bên cạnh đó, việc tham khảo ý kiến những chuyên gia có kinh nghiệm trong việc thiết kế bảng hỏi là điều cần thiết để có một bảng hỏi đạt yêu cầu.
Bước 7: Chỉnh sửa và hoàn thiện bảng hỏi
Thực hiện xong bước 6, người nghiên cứu cần những điều chỉnh cần thiết để có một bảng hỏi tốt. Sự điều chỉnh nhằm khắc phục các lỗi từ việc khảo sát thử hoặc được các chuyên gia góp ý. Một bảng hỏi tốt có thể mất nhiều lần phỏng vấn thử và điều chỉnh cho tới khi hoàn thiện. Sau khi có sự đồng thuận về bảng hỏi hoàn chỉnh, lúc này chúng ta mới bắt đầu tiến hành khảo sát thực tế. Cần lưu ý rằng kể từ lúc này, người làm nghiên cứu sẽ không chỉnh sửa bảng câu hỏi nữa để tạo sự nhất quán trong dữ liệu thu thập được (trừ trường hợp bảng hỏi mắc sai lầm mang tính trọng yếu).
2. Một số vấn đề cần lưu ý khi thành lập bảng hỏi
2.1. Chỉ sử dụng điều tra xã hội học để tìm kiếm loại thông tin phù hợp. Các câu hỏi chứa đựng quá nhiều thông số có thể có nhiều giá trị khác nhau đối với từng người tham gia trả lời, cũng như quy định lỏng lẻo đối với người trả lời (chọn bao nhiêu câu tuỳ thích) khiến kết quả thu được chỉ là một bức tranh được phát hoạ theo trí tưởng tượng và theo thị hiếu của mỗi người.
2.2. Chỉ hỏi những gì người được hỏi có năng lực trả lời. Nguyên tắc này quyết định tính chất đáng tin cậy của kết quả điều tra. Thật vậy, ai cũng đều biết rằng có một mối quan hệ chặt chẽ giữa thông tin cần tìm kiếm và đối tượng điều tra vì vậy không thể đặt mọi câu hỏi cho bất kỳ đối tượng nào, vì không thể có người biết mọi chuyện hoặc có khả năng phán xét (và nhất là phán xét đúng đắn) mọi chuyện.
2.3. Người được hỏi phải hiểu rõ câu hỏi. Để thông tin thu thập được chính xác, người hỏi và người trả lời phải có cùng một ngôn ngữ (hiểu theo nghĩa rộng). Nguyên tắc này nhằm để tránh trường hợp người trả lời không hiểu ý (hoặc hiểu khác ý) người hỏi. Vì thế, để bảo đảm là người trả lời hiểu đúng câu hỏi, phải tránh sử dụng những khái niệm có thể hiểu theo nhiều cách.
2.4. Thông tin mà người trả lời cung cấp không phải lúc nào cũng chính xác. Mức độ chính xác của thông tin có được từ các trả lời cho bảng câu hỏi tuỳ thuộc vào nhiều yếu tố. Dựa trên nguyên nhân của sự sai lệch, ta có thể phân làm hai loại sau đây: 1. Trả lời sai có ý thức: Người cung cấp thông tin cố tình cung cấp thông tin sai sự thật nhằm dụng ý riêng tư nào đó, chẳng hạn như khi người trả lời cảm thấy rằng câu hỏi có vẻ « đe dọa » đến đời tư của họ, thì họ sẽ cho câu trả lời không chính xác. Bảng câu hỏi là một công cụ không thể thiếu được trong nghiên cứu khoa học xã hội và nhân văn, nhưng (...) là một công cụ rất mong manh. Tính chất mong manh ấy nằm ở chỗ các câu trả lời của người được hỏi đôi khi thiếu tính ổn định khi họ cảm thấy bị đe dọa.Thật vậy, nếu người thầy đặt câu hỏi sau đây cho một học sinh có thói quen quay cóp trong thi cử: « Khi làm bài thi, em có quay cóp không nếu không thuộc bài ? », trong nhiều trường hợp, câu trả lời nhận được là « Không ». Học sinh ấy đã không nói đúng sự thật, vì em cảm thấy không an toàn, ngay cả khi người đặt câu hỏi không phải là thầy giáo trực tiếp dạy học sinh đó. 2. Trả lời sai vô ý thức: Ngay cả trong trường hợp người cung cấp thông tin hoàn toàn có thiện chí trong việc trả lời bảng câu hỏi, thì kết quả thu thập được cũng chưa chắc đã chính xác.
2.5. Cách xây dựng bảng câu hỏi quyết định giá trị của thông tin thu được. Việc xây dựng bảng câu hỏi có ý nghĩa đặc biệt quan trọng đến kết quả thu thập được.
2.6. Nguyên tắc tự nguyện của người tham gia trả lời. Mục đích của bảng câu hỏi là nhận được câu trả lời, và hơn thế nữa, câu trả lời càng chính xác càng tốt. Vì thế sự hợp tác tự nguyện của người trả lời là yếu tố tiên quyết để bảo đảm chất lượng thông tin thu được. Nếu không tự nguyện, người trả lời sẽ trả lời qua quýt, không có tinh thần trách nhiệm, và vì thế sẽ làm sai lệch kết quả điều tra. Thế nhưng, trong thực tế, có rất nhiều cuộc điều tra được tổ chức thiếu nghiêm túc. Bảng câu hỏi được chuyển qua nhiều trung gian, người phân phát bảng câu hỏi thường không nằm trong nhóm nghiên cứu, nên không hiểu mục đích, tính chất và tầm quan trọng của công trình nghiên cứu, vì thế không làm cho người được hỏi nhận thức được vấn đề nghiên cứu, và do đó tinh thần hợp tác của họ cũng không cao.
3. Chọn mẫu
Kích thước mẫu (cỡ mẫu) của nghiên cứu càng lớn, sai số trong các ước lượng sẽ càng thấp, khả năng đại diện cho tổng thể càng cao. Tuy nhiên, việc thu thập cỡ mẫu lớn sẽ làm tiêu tốn nhiều thời gian, công sức, tiền bạc ở toàn bộ các khâu từ thu thập, kiểm tra, phân tích. Do đó việc chọn kích thước mẫu cần phải được xem xét một cách có cân nhắc để mọi thứ được cân bằng và hiệu quả. Sự lựa chọn cỡ mẫu sẽ phụ thuộc vào:
- Độ tin cậy cần có của dữ liệu. Nghĩa là mức độ chắc chắn rằng các đặc điểm của cỡ mẫu được chọn phải khái quát được cho đặc điểm tổng thể.
- Sai số mà nghiên cứu có thể chấp nhận được. Đó là độ chính xác chúng ta yêu cầu cho bất ký ước lượng được thực hiện trên mẫu.
- Các loại kiểm định, phân tích sẽ thực hiện. Một số kỹ thuật thống kê yêu cầu cỡ mẫu phải đạt một ngưỡng nhất định thì các ước lượng mới có ý nghĩa.
- Kích thước của tổng thể. Mẫu nghiên cứu sẽ cần chiếm một tỷ lệ nhất định so với kích thước của tổng thể.
3.1. Xác định số mẫu theo ước lượng tổng thể
Theo Yamane Taro (1967), việc xác định số mẫu sẽ được chia làm hai trường hợp: không biết tổng thể và biết được tổng thể.
a. Trường hợp không biết quy mô tổng thể
Chúng ta sẽ sử dụng công thức sau:
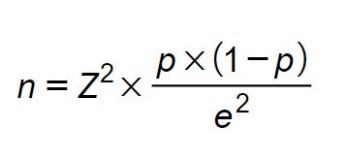
Trong đó:
· n: số mẫu cần xác định.
· Z: giá trị tra bảng phân phối Z dựa vào độ tin cậy lựa chọn. Thông thường, độ tin cậy được sử dụng là 95% tương ứng với Z = 1.96.
· p: tỷ lệ ước lượng cỡ mẫu n thành công. Thường chúng ta chọn p = 0.5 để tích số p(1-p) là lớn nhất, điều này đảm bảo an toàn cho mẫu n ước lượng.
· e: sai số cho phép. Thường ba tỷ lệ sai số hay sử dụng là: ±01 (1%), ±0.05 (5%), ±0.1 (10%), trong đó mức phổ biến nhất là ±0.05.
Ví dụ: Nghiên cứu sự hài lòng của khách hàng đã dùng sản phẩm nước giải khát Pepsi Cola tại TP.HCM. Đây là tổng thể không xác định được quy mô vì chúng ta không biết được có bao nhiêu khách hàng đã uống nước Pepsi Cola ở TP.HCM. Như vậy cỡ mẫu tối thiểu cần có của nghiên cứu sẽ là 385 người:
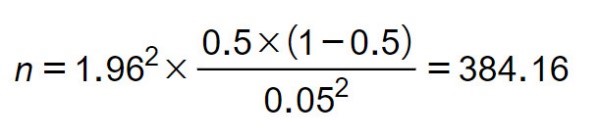
3.2. Trường hợp biết quy mô tổng thể
Công thức Slovin (1960)
Chúng ta sẽ sử dụng công thức sau:
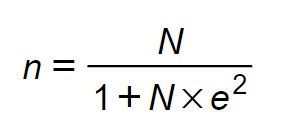
Trong đó:
· n: số mẫu cần xác định.
· N: quy mô tổng thể.
· e: sai số cho phép. Thường ba tỷ lệ sai số hay sử dụng là: ±0.01 (1%), ±0.05 (5%), ±0.1 (10%), trong đó mức phổ biến nhất là ±0.05.
Ví dụ: Nghiên cứu sự hài lòng của khách hàng đã mua sữa bột Ensure Gold trong tháng 8 năm 2020 tại siêu thị Coopmart. Siêu thị tổng hợp danh sách khách hàng từ hệ thống thì có 1000 khách hàng, đây là tổng thể xác định được quy mô. Như vậy cỡ mẫu tối thiểu cần có của nghiên cứu nếu sai số e = ±0.05 sẽ là 286 người:
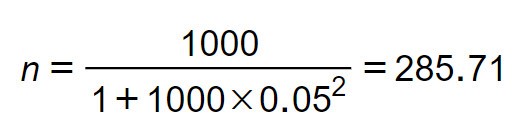
3. 3. Xác định số mẫu theo phân tích nhân tố khám phá (EFA)
( Phân tích EFA sẽ được trình bày ở bài khác)
Theo Hair và cộng sự (2014), kích thước mẫu tối thiểu để sử dụng EFA là 50, tốt hơn là từ 100 trở lên. Tỷ lệ mẫu quan sát trên một biến phân tích là 5:1 hoặc 10:1, một số nhà nghiên cứu cho rằng tỷ lệ này nên là 20:1 ; “biến phân tích” là một câu hỏi đo lường trong bảng khảo sát. Ví dụ, nếu bảng khảo sát của chúng ta có 30 câu hỏi sử dụng thang đo Likert 5 mức độ (tương ứng với 30 biến phân tích thuộc các nhân tố khác nhau), 30 câu này được sử dụng để phân tích trong một lần EFA. Áp dụng tỷ lệ 5:1, cỡ mẫu tối thiểu sẽ là 30 × 5 = 150, nếu tỷ lệ 10:1 thì cỡ mẫu tối thiểu là là 30 × 5 = 300. Kích thước mẫu này lớn hơn kích thước tối thiểu 50 hoặc 100, vì vậy chúng ta cần cỡ mẫu tối thiểu để thực hiện phân tích nhân tố khám phá EFA là 150 hoặc 300 tùy tỷ lệ lựa chọn dựa trên khả năng có thể khảo sát được.
3.4. Kích thước mẫu theo hồi quy
Đối với kích thước mẫu tối thiểu cho phân tích hồi quy, Green (1991) đưa ra hai trường hợp. Trường hợp một, nếu mục đích phép hồi quy chỉ đánh giá mức độ phù hợp tổng quát của mô hình như R2, kiểm định F … thì cỡ mẫu tối thiểu là 50 + 8m (m là số lượng biến độc lập hay còn gọi là predictor tham gia vào hồi quy). Trường hợp hai, nếu mục đích muốn đánh giá các yếu tố của từng biến độc lập như kiểm định t, hệ số hồi quy … thì cỡ mẫu tối thiểu nên là 104 + m (m là số lượng biến độc lập). Lưu ý rằng, m là số biến độc lập chúng ta đưa vào phân tích hồi quy, không phải là số biến quan sát hay số câu hỏi của nghiên cứu. Giả sử chúng ta xây dựng bảng khảo sát gồm 4 biến độc lập (4 thang đo), mỗi thang đo biến độc lập này được đo lường bằng 5 câu hỏi Likert (5 biến quan sát), như vậy tổng cộng chúng ta có 20 biến quan sát. Sau bước phân tích EFA, 4 thang đo này vẫn giữ nguyên như lý thuyết ban đầu, điều này đồng nghĩa có 4 biến độc lập sẽ được sử dụng cho phân tích hồi quy, tức m = 4 không phải m = 20.
Harris (1985) cho rằng cỡ mẫu phù hợp để chạy hồi quy đa biến phải bằng số biến độc lập cộng thêm ít nhất là 50. Ví dụ, phép hồi quy có 4 biến độc lập tham gia, thì cỡ mẫu tối thiểu phải là 4 + 50 = 54. Hair và cộng sự (2014) cho rằng cỡ mẫu tối thiểu nên theo tỷ lệ 5:1, tức là 5 quan sát cho một biến độc lập. Như vậy, nếu có 4 biến độc lập tham gia vào hồi quy, cỡ mẫu tối thiểu sẽ là 5 x 4 = 20. Tuy nhiên, 5:1 chỉ là cỡ mẫu tối thiểu cần đạt, để kết quả hồi quy có ý nghĩa thống kê cao hơn, cỡ mẫu lý tưởng nên theo tỷ lệ 10:1 hoặc 15:1. Riêng với trường hợp sử dụng phương pháp đưa biến vào lần lượt Stepwise trong hồi quy, cỡ mẫu nên theo tỷ lệ 50:1.
Nếu một bài nghiên cứu sử dụng kết hợp nhiều phương pháp xử lý thì sẽ lấy kích thước mẫu cần thiết lớn nhất trong các phương pháp. Ví dụ, nếu bài nghiên cứu vừa sử dụng phân tích EFA và vừa phân tích hồi quy. Kích thước mẫu cần thiết của EFA là 200, kích thước mẫu cần thiết của hồi quy là 100, chúng ta sẽ chọn kích thước mẫu cần thiết của nghiên cứu là 200 hoặc từ 200 trở lên.Thường chúng ta sử dụng phân tích EFA cùng với phân tích hồi quy trong cùng một bài luận văn, một bài nghiên cứu. EFA luôn đòi hỏi cỡ mẫu lớn hơn rất nhiều so với hồi quy, chính vì vậy chúng ta có thể sử dụng công thức tính kích thước mẫu tối thiểu cho EFA làm công thức tính kích thước mẫu cho nghiên cứu. Cũng lưu ý rằng, đây là cỡ mẫu tối thiểu, nếu chúng ta sử dụng cỡ mẫu lớn hơn kích thước tối thiểu, nghiên cứu sẽ càng có giá trị.
4. Chọn mẫu
– Xác định khung chọn mẫu hay danh sách chọn mẫu: Các khung chọn mẫu có sẵn, thường được sử dụng là: Các danh bạ điện thoại hay niên giám điện thoại xếp theo tên cá nhân, công ty, doanh nghiệp, cơ quan; các niên giám điện thoại xếp theo tên đường, hay tên quận huyện thành phố; danh sách liên lạc thư tín: hội viên của các câu lạc bộ, hiệp hội, độc giả mua báo dài hạn của các toà soạn báo…; danh sách tên và địa chỉ khách hàng có liên hệ với công ty (thông qua phiếu bảo hành), các khách mời đến dự các cuộc trưng bày và giới thiệu sản phẩm
– Lựa chọn phương pháp chọn mẫu: Dựa vào mục đích nghiên cứu, tầm quan trọng của công trình nghiên cứu, thời gian tiến hành nghiên cứu, kinh phí dành cho nghiên cứu, kỹ năng của nhóm nghiên cứu,… để quyết định chọn phương pháp chọn mẫu xác suất hay phi xác suất; sau đó tiếp tục chọn ra hình thức cụ thể của phương pháp này. Đi sâu vào phương pháp chọn mẫu ta có 2 phương pháp chọn mẫu cơ bản là :
4.1. Phương pháp chọn mẫu ngẫu nhiên (probability sampling methods)
Chọn mẫu ngẫu nhiên (hay chọn mẫu xác suất) là phương pháp chọn mẫu mà khả năng được chọn vào tổng thể mẫu của tất cả các đơn vị của tổng thể đều như nhau. Đây là phương pháp tốt nhất để ta có thể chọn ra một mẫu có khả năng đại biểu cho tổng thể. Vì có thể tính được sai số do chọn mẫu, nhờ đó ta có thể áp dụng được các phương pháp ước lượng thống kê, kiểm định giả thuyết thống kê trong xử lý dữ liệu để suy rộng kết quả trên mẫu cho tổng thể chung
Tuy nhiên ta khó áp dụng phương pháp này khi không xác định được danh sách cụ thể của tổng thể chung (ví dụ nghiên cứu trên tổng thể tiềm ẩn); tốn kém nhiều thời gian, chi phí, nhân lực cho việc thu thập dữ liệu khi đối tượng phân tán trên nhiều địa bàn cách xa nhau,…
* Các phương pháp chọn mẫu ngẫu nhiên:
4.1.1. Chọn mẫu ngẫu nhiên đơn giản (simple random sampling)
Trước tiên lập danh sách các đơn vị của tổng thể chung theo một trật tự nào đó : lập theo vần của tên, hoặc theo quy mô, hoặc theo địa chỉ…, sau đó đánh số thứ tự các đơn vị trong danh sách; rồi rút thăm, quay số, dùng bảng số ngẫu nhiên, hoặc dùng máy tính để chọn ra từng đơn vị trong tổng thể chung vào mẫu.
Thường vận dụng khi các đơn vị của tổng thể chung không phân bố quá rộng về mặt địa lý, các đơn vị khá đồng đều nhau về đặc điểm đang nghiên cứu. Thường áp dụng trong kiểm tra chất lượng sản phẩm trong các dây chuyền sản xuất hàng loạt.
4.1.2. Chọn mẫu ngẫu nhiên hệ thống (systematic sampling)
Trước tiên lập danh sách các đơn vị của tổng thể chung theo một trật tự quy ước nào đó, sau đó đánh số thứ tự các đơn vị trong danh sách. Đầu tiên chọn ngẫu nhiên 1 đơn vị trong danh sách ; sau đó cứ cách đều k đơn vị lại chọn ra 1 đơn vị vào mẫu,…cứ như thế cho đến khi chọn đủ số đơn vị của mẫu. Ví dụ : Dựa vào danh sách bầu cử tại 1 thành phố, ta có danh sách theo thứ tự vần của tên chủ hộ, bao gồm 240.000 hộ. Ta muốn chọn ra một mẫu có 2000 hộ. Vậy khoảng cách chọn là : k= 240000/2000 = 120, có nghĩa là cứ cách 120 hộ thì ta chọn một hộ vào mẫu.
4.1.3. Chọn mẫu cả khối (cluster sampling)
Trước tiên lập danh sách tổng thể chung theo từng khối (như làng, xã, phường, lượng sản phẩm sản xuất trong 1 khoảng thời gian…). Sau đó, ta chọn ngẫu nhiên một số khối và điều tra tất cả các đơn vị trong khối đã chọn. Thường dùng phương pháp này khi không có sẵn danh sách đầy đủ của các đơn vị trong tổng thể cần nghiên cứu. Ví dụ : Tổng thể chung là sinh viên của một trường đại học. Khi đó ta sẽ lập danh sách các lớp chứ không lập danh sách sinh viên, sau đó chọn ra các lớp để điều tra.
4.1.4. Chọn mẫu phân tầng (stratified sampling)
Trước tiên phân chia tổng thể thành các tổ theo 1 tiêu thức hay nhiều tiêu thức có liên quan đến mục đích nghiên cứu (như phân tổ các DN theo vùng, theo khu vực, theo loại hình, theo quy mô,…). Sau đó trong từng tổ, dùng cách chọn mẫu ngẫu nhiên đơn giản hay chọn mẫu hệ thống để chọn ra các đơn vị của mẫu. Đối với chọn mẫu phân tầng, số đơn vị chọn ra ở mỗi tổ có thể tuân theo tỷ lệ số đơn vị tổ đó chiếm trong tổng thể, hoặc có thể không tuân theo tỷ lệ. Ví dụ : Một toà soạn báo muốn tiến hành nghiên cứu trên một mẫu 1000 doanh nghiệp trên cả nước về sự quan tâm của họ đối với tờ báo nhằm tiếp thị việc đưa thông tin quảng cáo trên báo. Toà soạn có thể căn cứ vào các tiêu thức : vùng địa lý (miền Bắc, miền Trung, miền Nam) ; hình thức sở hữu (quốc doanh, ngoài quốc doanh, công ty 100% vốn nước ngoài,…) để quyết định cơ cấu của mẫu nghiên cứu.
4.1.5. Chọn mẫu nhiều giai đoạn (multi-stage sampling)
Phương pháp này thường áp dụng đối với tổng thể chung có quy mô quá lớn và địa bàn nghiên cứu quá rộng. Việc chọn mẫu phải trải qua nhiều giai đoạn (nhiều cấp). Trước tiên phân chia tổng thể chung thành các đơn vị cấp I, rồi chọn các đơn vị mẫu cấp I. Tiếp đến phân chia mỗi đơn vị mẫu cấp I thành các đơn vị cấp II, rồi chọn các đơn vị mẫu cấp II…Trong mỗi cấp có thể áp dụng các cách chọn mẫu ngẫu nhiên đơn giản, chọn mẫu hệ thống, chọn mẫu phân tầng, chọn mẫu cả khối để chọn ra các đơn vị mẫu.
Ví dụ: Muốn chọn ngẫu nhiên 50 hộ từ một thành phố có 10 khu phố, mỗi khu phố có 50 hộ. Cách tiến hành như sau: Trước tiên đánh số thứ tự các khu phố từ 1 đến 10, chọn ngẫu nhiên trong đó 5 khu phố. Đánh số thứ tự các hộ trong từng khu phố được chọn. Chọn ngẫu nhiên ra 10 hộ trong mỗi khu phố ta sẽ có đủ mẫu cần thiết.
4.2. Phương pháp chọn mẫu phi ngẫu nhiên (non-probability sampling methods)
Chọn mẫu phi ngẫu nhiên (hay chọn mẫu phi xác suất) là phương pháp chọn mẫu mà các đơn vị trong tổng thể chung không có khả năng ngang nhau để được chọn vào mẫu nghiên cứu. Chẳng hạn: Ta tiến hành phỏng vấn các bà nội trợ tới mua hàng tại siêu thị tại một thời điểm nào đó; như vậy sẽ có rất nhiều bà nội trợ do không tới mua hàng tại thời điểm đó nên sẽ không có khả năng được chọn
Việc chọn mẫu phi ngẫu nhiên hoàn toàn phụ thuộc vào kinh nghiệm và sự hiểu biết về tổng thể của người nghiên cứu nên kết quả điều tra thường mang tính chủ quan của người nghiên cứu. Mặt khác, ta không thể tính được sai số do chọn mẫu, do đó không thể áp dụng phương pháp ước lượng thống kê để suy rộng kết quả trên mẫu cho tổng thể chung
Các phương pháp chọn mẫu phi ngẫu nhiên
4.2.1. Chọn mẫu thuận tiện (convenience sampling)
Có nghĩa là lấy mẫu dựa trên sự thuận lợi hay dựa trên tính dễ tiếp cận của đối tượng, ở những nơi mà nhân viên điều tra có nhiều khả năng gặp được đối tượng. Chẳng hạn nhân viên điều tra có thể chặn bất cứ người nào mà họ gặp ở trung tâm thương mại, đường phố, cửa hàng,.. để xin thực hiện cuộc phỏng vấn. Nếu người được phỏng vấn không đồng ý thì họ chuyển sang đối tượng khác. Lấy mẫu thuận tiện thường được dùng trong nghiên cứu khám phá, để xác định ý nghĩa thực tiễn của vấn đề nghiên cứu; hoặc để kiểm tra trước bảng câu hỏi nhằm hoàn chỉnh bảng; hoặc khi muốn ước lượng sơ bộ về vấn đề đang quan tâm mà không muốn mất nhiều thời gian và chi phí.
4.2.2. Chọn mẫu phán đoán (judgement sampling)
Là phương pháp mà phỏng vấn viên là người tự đưa ra phán đoán về đối tượng cần chọn vào mẫu. Như vậy tính đại diện của mẫu phụ thuộc nhiều vào kinh nghiệm và sự hiểu biết của người tổ chức việc điều tra và cả người đi thu thập dữ liệu. Chẳng hạn, nhân viên phỏng vấn được yêu cầu đến các trung tâm thương mại chọn các phụ nữ ăn mặc sang trọng để phỏng vấn. Như vậy không có tiêu chuẩn cụ thể “thế nào là sang trọng” mà hoàn toàn dựa vào phán đoán để chọn ra người cần phỏng vấn.
4.2.3. Chọn mẫu định ngạch (quota sampling)
Đối với phương pháp chọn mẫu này, trước tiên ta tiến hành phân tổ tổng thể theo một tiêu thức nào đó mà ta đang quan tâm, cũng giống như chọn mẫu ngẫu nhiên phân tầng, tuy nhiên sau đó ta lại dùng phương pháp chọn mẫu thuận tiện hay chọn mẫu phán đoán để chọn các đơn vị trong từng tổ để tiến hành điều tra. Sự phân bổ số đơn vị cần điều tra cho từng tổ được chia hoàn toàn theo kinh nghiệm chủ quan của người nghiên cứu. Chẳng hạn nhà nghiên cứu yêu cầu các vấn viên đi phỏng vấn 800 người có tuổi trên 18 tại 1 thành phố. Nếu áp dụng phương pháp chọn mẫu định ngạch, ta có thể phân tổ theo giới tính và tuổi như sau:chọn 400 người (200 nam và 200 nữ) có tuổi từ 18 đến 40, chọn 400 người (200 nam và 200 nữ) có tuổi từ 40 trở lên. Sau đó nhân viên điều tra có thể chọn những người gần nhà hay thuận lợi cho việc điều tra của họ để dễ nhanh chóng hoàn thành công việc.
TÀI LIỆU THAM KHẢO
1. Ryan, T. (2013). Sample Size Determination and Power. John Wiley and Sons.
2. Yamane, Taro. (1967). Statistics: An Introductory Analysis, 2nd Edition, New York: Harper and Row.
3. Hair và cộng sự, Multivariate Data Analysis, Pearson, New Jersey, 2014.
4. Green & Salkind, Using SPSS for Windows and Macintosh: Analyzing and Understanding Data, Prentice Hall, New Jersey, 2003.
5. Harris, A primer of multivariate statistics, New York: Academic Press,1985.
6. Hair và cộng sự, Multivariate Data Analysis, Pearson, New Jersey, 2014
7. Kotler, N. & Kotler, P. 1998, Museum Strategy and Marketing: Designing Missions, Building Audiences, Generating Revenue and Resources, Jossey-Bass, San Francisco.
TS. Vũ Thị Thanh Thủy